The Bitter Lesson: How Your Intuition About AI Is Probably Wrong
The Bitter Lesson is a short essay1 containing the most important idea in artificial intelligence from the past 20 years. It’s relevant to you if you work in an AI-heavy field, invest in AI-powered companies, or are just curious about this technology that’s taken our culture by storm. In one sentence, the bitter lesson says: AI systems that depend on powerful computers will beat clever systems that depend on human-curated knowledge.
The bitter lesson is an idea so powerful it’s already reshaping our world, from concrete business decisions all the way down to philosophical questions like “what does it mean to think?” Our intuition about AI systems is often wrong and the bitter lesson is often a helpful way to frame things. One of my favorite examples of the bitter lesson is computer chess, which illustrates many implications of the bitter lesson, including something you’re probably already wondering: why is it so “bitter”?
Computer chess
We, humanity, have been teaching machines to play chess for a hundred years. Up until very recently, this meant knowledge engineering, or encoding human knowledge inside an algorithm.

The first real chess computer: El Ajedrecista, 1912
Here’s how knowledge engineering works: you talk to many strong human chess masters and you ask them about chess: why is this move better than that move? Why is your knight better than their bishop? When do you decide to attack? How do you know if your king is safe? Then you write a set of approximate guidelines, or heuristics, for the computer to automatically evaluate a position. This is a clever approach, because it relies quite a bit on human cleverness. It depends on whatever knowledge the chess masters have in their brains.
To be fair, you can make a lot of progress with clever methods! In 1997, Deep Blue became the first computer program to beat a human chess champion (Garry Kasparov) in a full chess match. It relied heavily on these human-influenced heuristics, combined with its ability to evaluate millions of possible positions with those heuristics. In the 20 years after Deep Blue’s victory, computers went from “stronger than the human champion” to “basically no human will ever win a game of chess against a computer again”.

It seemed like we’d figured out basically everything important there was to know about chess. Then came AlphaZero, the algorithm that shook the computer chess world.
While the rest of the world was focused on smarter and smarter ways of translating human knowledge into computer code, in 2017 an AI research lab named DeepMind was focused in another direction. Instead of directly teaching the computer how to play chess, they created a deep learning algorithm that learns from playing games against itself. AlphaZero started without knowing any strategy, tactics, creativity, or human advisors to lean on, but it could truly take advantage of thousands of Google’s powerful TPU computer chips by playing many games in a short period of time.
When AlphaZero finished training (after just nine hours!), DeepMind set up a 100-game match featuring AlphaZero versus Stockfish. In 2017, Stockfish was the crown jewel of computer chess, the great peak of all human chess knowledge from the past fifteen centuries. It was the strongest chess engine in the world, far beyond any human player. The final result: AlphaZero 28 wins, Stockfish zero.2
The bitter lesson in computer chess
- The bitter lesson is a long-term guideline. Over the long-term, general AI systems that take advantage of compute beat hand-crafted systems that depend on humans directly injecting their knowledge.
In other words, in the short term it’s easy to be tricked by short-term results and small experiments! For over a hundred years, clever algorithms were stronger than bitter-lesson-style systems. AlphaZero wasn’t the first attempt to make neural networks work well, but in the 1970s and 1980s the computers just weren’t powerful enough to show off what neural nets can do. Beware of assuming there’s something magical in human brain-power that machines can’t imitate. Computers still struggle with a huge number of tasks, but present-day obstacles are only weak evidence for what the future will be like.
- The bitter lesson means advances in AI depend heavily on the computing hardware you have.
When I first started studying machine learning, the syllabus focused on mathematical ideas, so I focused on mathematical ideas. But the bitter lesson tells us that the best AI systems make great use of increasing computing power, so building powerful AI means combining hardware3 and software in collaboration with linear algebra, probability, and statistics. I think it’s a mistake to assume you can only contribute to AI if you have a PhD in math, and the bitter lesson is why. I tell every “regular” software engineer who’s interested in AI to just start reading code and research papers instead of waiting for a teacher to start teaching them.
- The bitter lesson is bitter.
It’s pretty common to be uncomfortable when thinking about the bitter lesson. The idea that a computer can be better than a human in something that seems to require true creativity or cleverness?
The history of chess goes like this: 1500 years of humans being the strongest, then 10-15 years of unbeatable computers but we still had to actively teach them how to win, then in the past 10 years all world-class programs contain some neural network components that learn from a pile of training data with little human intervention. Losing at chess can be painful, but it can be worse if you’ve spent a lifetime studying the game, taking so much knowledge for granted, and then learning from the computer that there’s a lot you still don’t know, and probably never will. It’s also a bit bittersweet for the researchers and engineers who create these programs!
- The bitter lesson does not guarantee that your model will succeed. It’s only a general trend.
Modern day chess engines use neural networks rather than hand-crafted heuristics to help them make decisions, but unlike AlphaZero, these neural networks tend to be smaller and limited. The bitter lesson is about taking advantage of scaling compute to discover solutions that humans alone wouldn’t find, not purely about grabbing the most powerful computing cluster that money can buy. Unfortunately, the bitter lesson on its own isn’t a very useful instruction for AI research, because if you follow it too strongly you might just end up wasting compute on a bad research direction. It only tells us generally where AI is headed.
Also, a lot of software wasn’t written using bitter-lesson inspired AI models at all– including, for example, the operating system that AlphaZero ran on.
Other notable examples of the bitter lesson
- PDF processing
Many companies offer services that sound like this: you give them a PDF (or many PDFs), then they extract useful information and organize it for you.
PDFs can be complicated! In the past, this required you to use a complicated mix of algorithms. You had to detect text with optical character recognition (OCR), figure out how the pages are organized (is there one column or two?), figure out how to read tables and graphs and charts, and so on. Each step along the way was an additional place for errors to creep in and ruin the output.
These days, you’re better off feeding the PDF directly into a vision-language model (VLM) and directly asking it questions. Not only can you write a working solution more quickly, this method is almost always much more accurate than the complex solutions from the past. Hand-made OCR pipelines lose. VLMs trained with big data, big compute, and big power win.
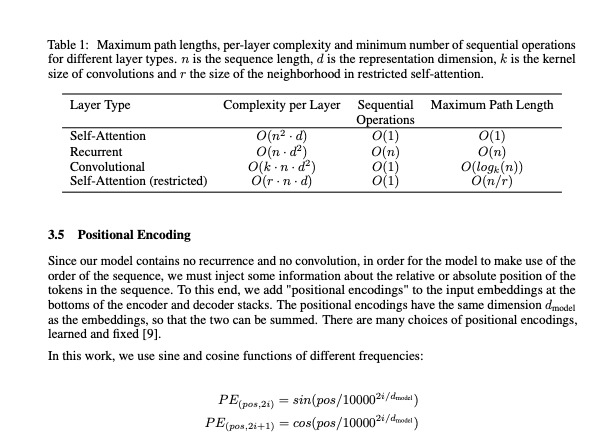
A screenshot from the landmark research paper Attention is All You Need on attention in transformer neural networks.

And here’s what ChatGPT said about it when I provided a screenshot of the paper with no further hints.
- BloombergGPT
Bloomberg is a large, well-known software and finance company. In 2023, a research team carefully fine-tuned an existing LLM (OpenAI’s GPT-3.5) to create an AI system specifically designed for finance named BloombergGPT. Not long after, some researchers compared its performance to OpenAI’s GPT-4, a model that used more computing power, more training data, more trained parameters, and was generally more capable. It turns out GPT-4 was better, even for finance-specific questions, than the human ingenuity that went into fine-tuning GPT-3.5.
- Poker
We used to hear a lot that AI can’t handle psychology the way it can handle logic. This objection is wrong. It might seem like a computer should only be able to understand the logic of chess, not the bluffing, deception, and incomplete information of poker, but that hasn’t stopped the bitter lesson from showing up here too.
Poker bots used to be like chess engines, filled with human-encoded knowledge, but humans could still beat them without too much trouble. In 2015, researchers at Carnegie Mellon University created an AI named Claudico to play no-limit Texas hold’em poker against top-level humans. Claudico trained for several million core-hours4 and finish fourth out of 5 players. 2 years later, they trained Libratus on about 5 times as much compute, which competed again in 1-on-1 games versus top humans. During the tournament, other poker players bet on the outcome– initially 4:1 odds against the bot, but near the end, they were betting on which human would lose the least badly. Two years after Libratus came Pluribus, also trained by playing against itself (sound familiar?). Pluribus was ready to take on the complexity of a game with many players and beat top-level humans so decisively that the developers decided to not release the code, just to reduce cheating in online poker between humans.
I got to briefly chat with a lead researcher behind these poker projects in 2023. He mentioned that he didn’t see any obvious reason for the trend of AI in games to change. He noted that we might be in the timeline where the bitter lesson is coming not only for chess and poker, but also every game that we bother to play.
Practical implications
The bitter lesson is a big deal. We’ll discuss some of its most important implications, first from the perspective of a regular person who’s just curious about its direction, then for people who work and invest in companies in the field.
Unexpected knowledge
The bitter lesson means we should expect our AI models, increasingly often, to have unexpected capabilities. They have an astounding amount of knowledge about the world, and it’s very often a serious mistake to assume its behavior can always be precisely defined or predicted by the AI’s creators.
For a lot of people, AI chatbots probably started feeling uncannily human in 2023 when the first version of ChatGPT was released. These days you can open a web browser and start talking to any leading AI model (ChatGPT from OpenAI, Claude from Anthropic, Gemini from Google, Llama from Meta, etc), and they can all complete your sentences in a strangely human way. No human explicitly trained all this functionality into the AI.
I’m already seeing story after story of people having a bad day and rambling to their favorite AI language model, and the advice they get ends up being perfectly tuned to the context of the situation. No one wrote code specifically for “AI empathy”; there are simply enough examples of good conversations in the training data for the AI to pick up on our emotional patterns that leak out in text.
agi is shorthand for artificial general intelligence, or AI that is as smart as a human in basically every domain. Claude refers to Claude 3.5 Sonnet, a remarkable model from Anthropic.
This isn’t limited to language-only AI. For instance: no one explicitly taught the AI about the concept of shadows. Shovel enough data into the model and it ends up figuring it out.
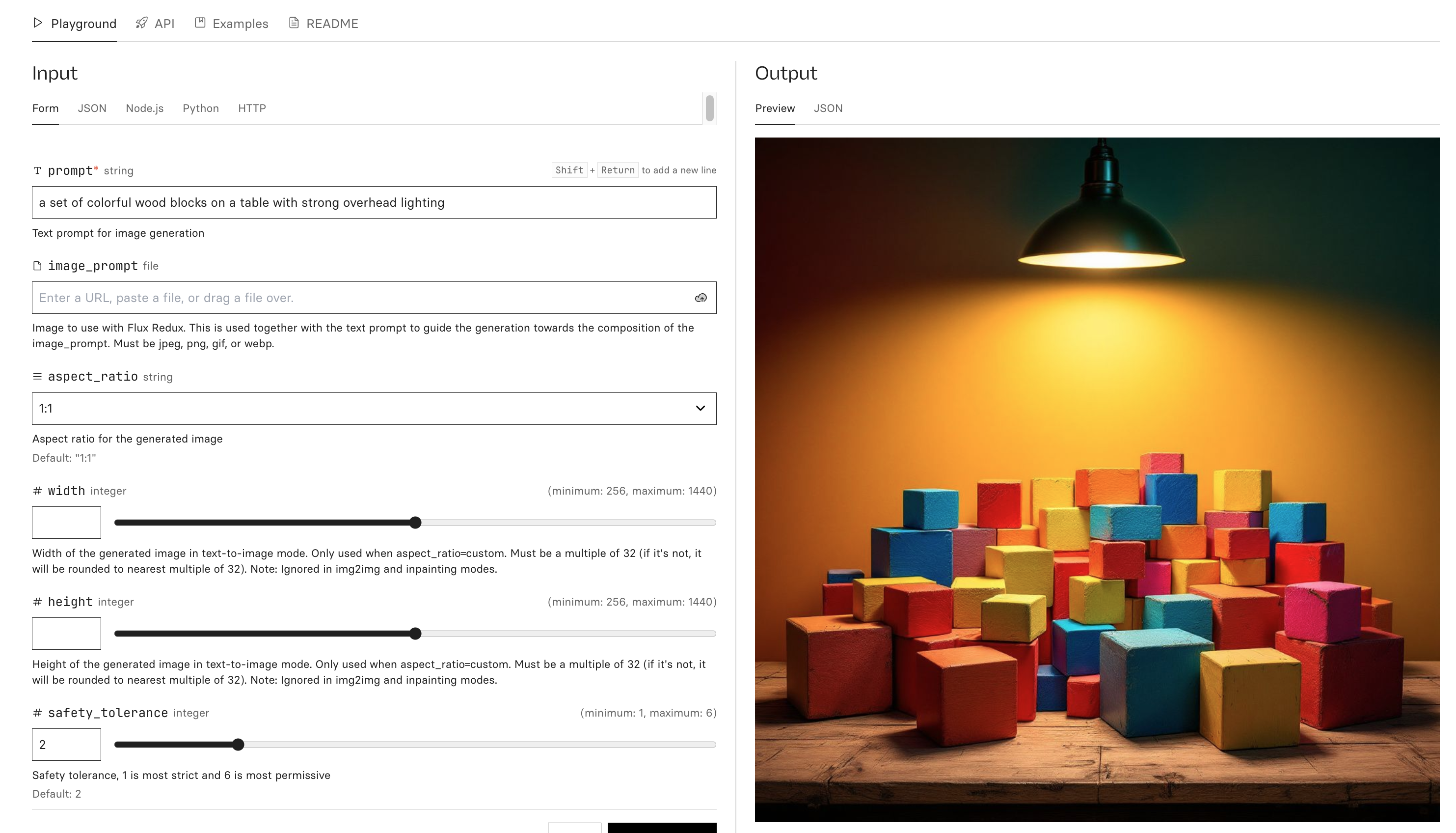
This is the Flux-1.1-pro model on Replicate. I typed in some words and it produced this picture with no further guidance on my part.
Or how about the fact that the AI can tell where you are in the world just from a single picture with no obvious hints to ordinary humans?
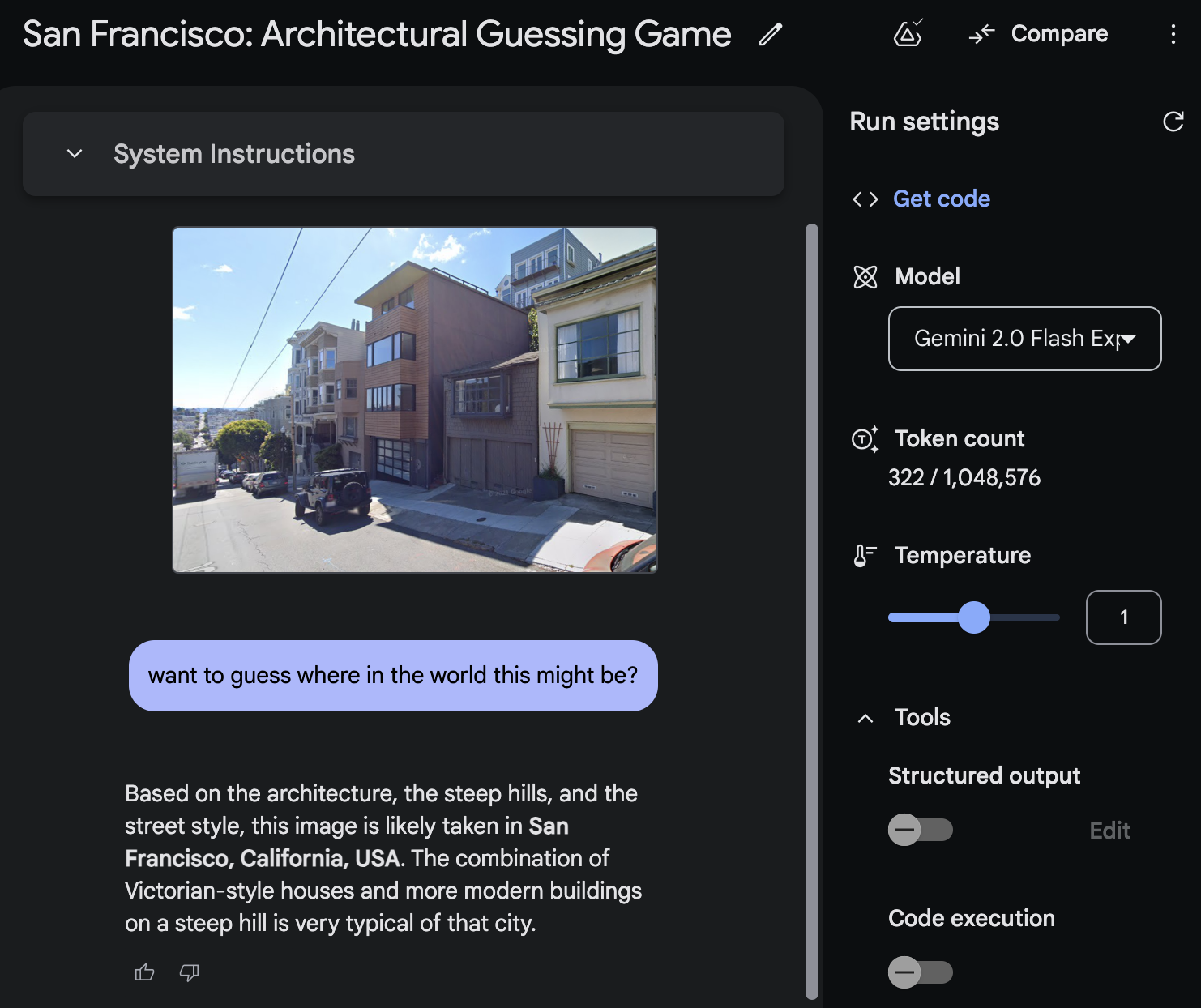
A screenshot from Google Maps, near 985 Union Street in San Francisco, California
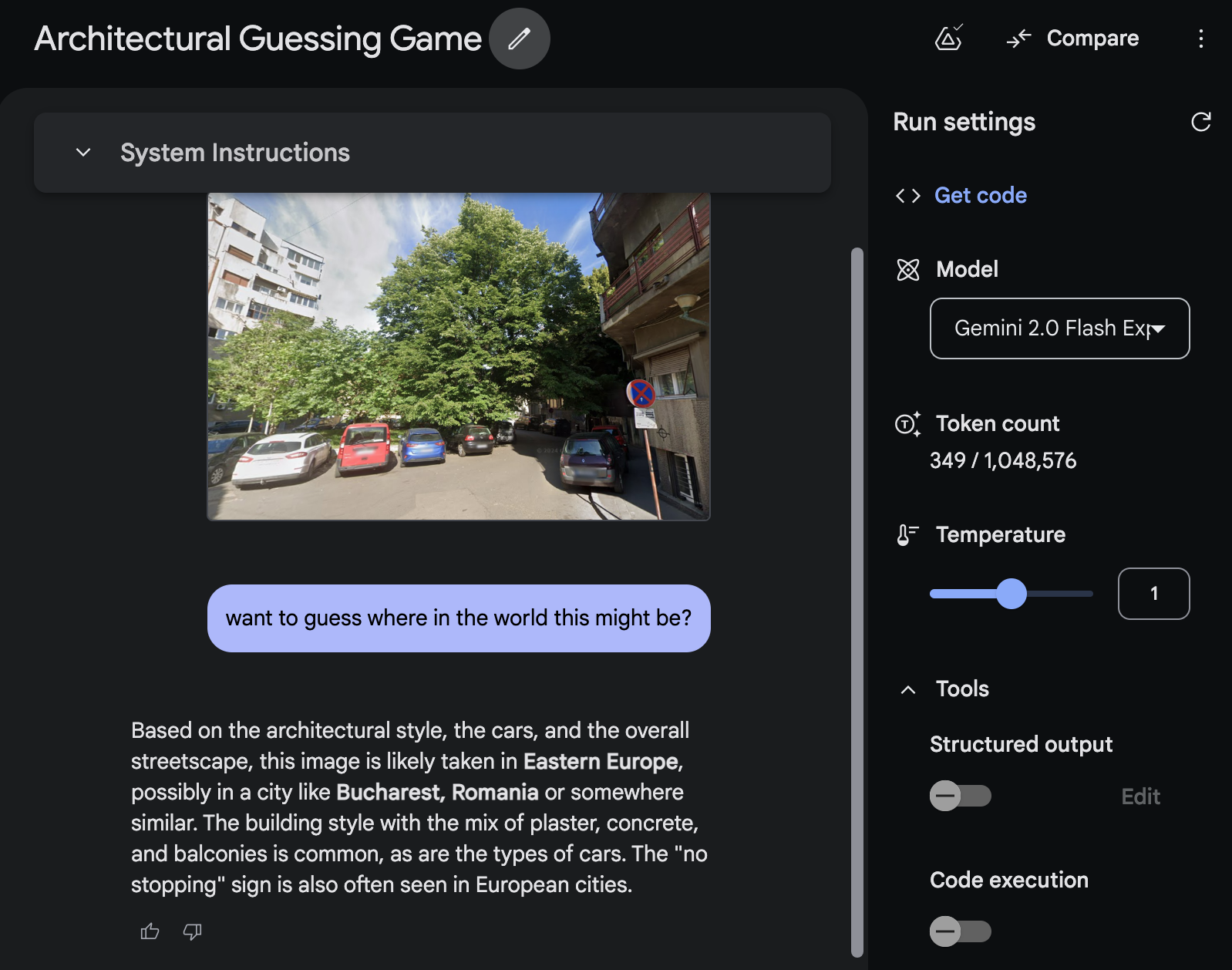
If you were curious: 11 Strada Stelea Spătarul, Bucharest, Romania
These aren’t just neat tech demos– these are moments when you realize the bitter lesson lets it learn things that no ordinary human would easily pick up. Expect future AI to continue to uncover patterns like this, and try not to get too unnerved when it seems to perceive a faint outline of who you are after just a minute of conversation. Expect to discover that you’re leaking out much more information into the world than you thought you were.
Here’s the obvious follow-up: if you have something that can understand images and write code, then you have a system that can use a computer. All you’d have to do is just show the AI screenshots and have it write code to imitate mouse clicks, typing on a keyboard, and so on. It sounds very futuristic and fantastical, except this has already happened and everyone with a computer and an internet connection can use this.
https://x.com/nearcyan/status/1830027199619256455
https://x.com/rakyll/status/1866886887388090454
The bitter lesson means that we won’t know what exactly AI models can do, because there’s no list of abilities that an engineer specifically designed. We will instead discover what they can do, especially as they become more independent. As we start building more infrastructure designed for AI as well as humans, we may end up describing more abstract goals and leaving many details up to the computer.
I’ve already observed this for about two years in AI-assisted coding. These days, for many commonplace coding tasks, I just write a spec and leave all of the concrete coding up to the AI, and I just have to verify that it’s right. Just like a good software engineering manager can help their engineers with clarifying abstract goals, making plans, and so on, I expect management skills to become much more valuable when interfacing with AI.
Implications for software, businesses, and everything you work on
One thing always on the back of my mind is that many complex projects run the risk of getting bitter-lessoned. Complicated human-made procedures often end up getting replaced by AI models that scale with compute. Except, wait a minute, literally every single human business and organization is held together by many complicated human-made procedures.
To be clear, I’m not forecasting AI instantly taking over the world here. Tomorrow morning I expect to wake up to a world where the sun still rises in the normal spot in the sky and we’ll all go about our day. I’ve seen enough and learned enough to avoid saying words like impossible or never but I’m more interested here in the more practical implications of the bitter lesson for people working in software and especially AI today.
If you spend time making complex pipelines that manipulate data this way and that way, it’s easy to accidentally insert your biases about how you would solve a problem. It’s so natural to decide that, if you wanted to get good at analyzing financial documents, you’d curate a set of financial documents to feed into a machine. It’s intuitive to assume that if you want to detect emotion in text, you write down a big list of happy or sad or angry words as a reference. Often this is actually the correct thing to do because it’s cost-effective and gets the job done. But sometimes a well-resourced team somewhere pours a massive amount of resources into training the next-generation AI model and then the “stupid” approach of putting everything into one single model ends up working. As a direct result of the bitter lesson, you’re in an uncomfortable position, stuck between two extremes:
- You design everything so that it’s almost good enough and hope the next wave of improvements solves everything. But, as they say, “hope is not a strategy”.
- You work around weaknesses in current AI models and you get good results for now, but maybe the next generation makes all your old work irrelevant.
I don’t claim to know the future, but here’s how I like to think about it for my personal projects: it depends on urgency, cost, and how good the AI is today. If the AI is almost good enough today and I’m competing against others to show something off before anyone else can, then I might spend time working out all the sharp edges. Even if something much better comes out in three months and I end up having to throw all my work away, those three months might be valuable for some projects. If it’s not so urgent, I’ll probably do something else with my time.
One other silver lining for software engineers: a lot of your boring drudge work might end up getting resolved by the bitter lesson too. Software engineers like to talk about “tech debt”, when you make decisions that give you short-term gain for long-term pain. Paying off your tech debt means reorganizing your code so you can adapt it for its new purposes. This requires time and effort, and the opportunity cost is that you’re not spending your time and effort on making cool new things today.
As AI gets better at coding, maybe a lot of tech debt just disappears. More than once, I point the AI at a giant mess I made and tell it quite literally to “fix the mess”. It often ends up doing a great job! After the new version passes all my tests, I’m free to continue with the more interesting and impactful work I wanted to do.
Conclusions
The bitter lesson is not intuitive. We assume specialists in a field are better than generalists in that area, but that’s not always true for AI. A model that’s better at using massive amounts of compute tends to end up winning, often even in the specialist domains.
The bitter lesson is bitter. Instinctively, we don’t want to believe the machine will have a soul, emotion, whatever. First it was “AI needs to have creativity to play chess”, and “AI needs to pass the Turing Test to truly be human-like”, and then it was “AI can’t make real art”. The important takeaway from the bitter lesson is not whatever opinion you have on these questions. The important takeaway is that we must not define ourselves by just one narrow thing, because one day a computer might come along and be better than you at that thing and then what is left?
And yet no AI can enjoy a masterpiece for me; for that I must enjoy it myself. context
The bitter lesson means intelligence is more complicated than we assume. Every time AI surprises us with a novel solution, it’s a reminder that our intuitions are often not the only way forward. The bitter lesson tells us that the capabilities in AI systems are truly alien. In the coming years, the bitter lesson may expose us to many AI systems that surprise us, make us laugh, sigh, and wonder. Hopefully we may learn a little more about what it means to think, what makes up a mind, and what it really, actually means to be human.
Notes
1: The Bitter Lesson was written by Rich Sutton, an absolute legend in AI, one of the creators of reinforcement learning. I tell people, only half-jokingly, to read the original essay out loud every day for a month. I always feel slightly queasy when someone working on or investing in an AI-powered project hasn’t spent some time thinking about the bitter lesson. It kind of feels like someone running into the ocean without knowing what swimming is.
2: The match also included 72 draws. For context, chess is a game that frequently ends in draws at the highest levels - top-level games between human grandmasters end in draws about a third to half of the time. That doesn’t make the result any less shocking– zero wins for Stockfish is an absolutely lopsided result.
Since AlphaZero, computer chess has drawn from the bitter lesson. Every top engine today uses some sort of neural networks, trained on data rather than hardcoded rules. They’ve continued to improve beyond our wildest imaginings. There used to be a form of chess called “centaur chess”, where you’d combine a strong human master with a strong computer– the idea being that even with a vastly superior computer program, the human could still find new ideas, making a human-computer team stronger than the computer alone.

Centaur chess is named after the centaur, a mythical creature with the body of a horse and the head of a human. In the context of chess, it resembles a human and non-human creature working together.
These days, however, top chess computers have simply gotten too strong. For the most part, we can’t even offer improvements to their play, because for everything we think of, the computer has thought of it too. Centaur chess mostly doesn’t exist anymore.
3: Here are two concrete examples of hardware affecting advances in AI:
- We invented neural networks in 1943. Why didn’t we have today’s AI by 1950? We didn’t have:
- the data (the internet is overflowing with data)
- the compute (GPUs didn’t even exist until 1999, Google only started using TPUs in 2015. both of these are custom-designed computer hardware that are incredibly good at doing huge amounts of computation)
- the infrastructure (these days, individual companies like Amazon or Meta build power plants to support their training runs. That didn’t happen in 1950!)
- the software libraries that would let you build and debug huge AI models (Pytorch? Tensorflow? forget about it).
- The fundamental operation in neural networks is matrix multiplication. There’s a bit of a chicken and egg problem here: almost all the big famous popular AI models today are neural networks, which benefit greatly from the type of computing hardware we have. But the hardware engineers often design their chips so that they’re well-suited to enabling neural networks! So who really has the most influence on the direction of AI, the machine learning grad student who trains a model on their GPU or the GPU designer making chips with the machine learning grad student in mind?
4: Core-hours is a way to measure how much computing power you’re using. For example, if you had 1 million cores all working for an hour, that would be 1 million core-hours of compute time.
Thank you to Claude 3.5 Sonnet for helping me revise and proofread. It is truly a remarkable model.